241004_order by到底走不走索引 ORDER BYは一体インデックスを使うのか?

很多时候,即使我们给某个字段设置了索引,但实际查询可能并没有走索引。
多くの場合、あるカラムにインデックスを設定していても、実際のクエリではインデックスが使用されないことがあります。
比如一个常见的案例就是,LIKE做模糊匹配时,如果通配符%在搜索字符串的左边,就会导致索引失效。
例えば、LIKEを使った部分一致検索の場合、検索文字列の先頭にワイルドカード(%)があると、インデックスが無効になってしまうケースがあります。

那回到主题,如果order by的字段已经设置了索引,那实际的query到底会不会走索引呢?
では本題に戻りますが、ORDER BYのカラムにインデックスが設定されている場合、実際のクエリでは本当にインデックスが使われるのでしょうか?
假设有一张论文表中有一个clicked_count字段,代表点击量。对clicked_count字段设置索引。我们的需求是在网站的首页显示点击量最高的10篇文章。
例えば、ある論文テーブルに「clicked_count」というカラムがあり、これは各論文のクリック数を表しています。この「clicked_count」カラムにはインデックスが設定されています。そして、私たちの要件は、ウェブサイトのトップページにクリック数が最も多い上位10件の論文を表示することです。
1 | CREATE INDEX idx_clicked_count ON gpt_simplify_paper(clicked_count); |
那我们很容易写出如下的SQL语句
そのため、次のようなSQL文を自然に思いつくでしょう。
1 | SELECT * FROM gpt_simplify_paper |
这条查询使用了索引吗?このクエリはインデックスを使用しているのでしょうか?
用EXPLAIN查看执行计划 EXPLAINで実行計画を確認しましょう

type是ALL,Extra是Using filesort,可见即使设置了索引也没有走索引
typeが「ALL」、Extraが「Using filesort」となっていることから、インデックスが設定されていても実際には使用されていないことが分かります。
那如果select只包含主键和索引字段呢?(刚才的select *还包括了其他的字段)
では、SELECTに主キーとインデックスが張られているカラムのみを含めた場合はどうなるでしょうか?(先ほどのSELECT *では、他のカラムも含まれていました)
1 | SELECT paper_id, clicked_count FROM gpt_simplify_paper |

结果使用了索引! 結果として、インデックスが使用されました!
分析:不加where条件时,大多数情况下指向的一定是全表扫描(ALL)。case1select *虽然sort的字段是有二级索引的,但如果走索引,仍然需要回表(因为select *还需要输出其他的字段),相比于回表的开销,肯定还是直接去聚簇索引拿回所有数据,再回内存排序更快一些。
case2SELECT paper_id, clicked_count需要的字段刚好二级索引idx_clicked_count都包含了,即覆盖索引,所以不需要回表,所以也没必要多此一举去走主键聚簇索引了。
分析:
WHERE条件がない場合、多くのケースでは全表スキャン(ALL)が選択される傾向にあります。
case1では、SELECT *においてソート対象のカラムには二次インデックスが設定されていますが、インデックスを使用すると「カバリング」されていないカラムを取得するためにテーブルアクセス(いわゆる「テーブルへの戻り」)が必要になります。この「戻り」のコストを考えると、最初からクラスタ化インデックスを使って全データを読み込み、メモリ上でソートした方がパフォーマンスが高いと判断されるため、インデックスは使われません。
case2では、SELECT paper_id, clicked_countと、要求されるカラムが二次インデックスidx_clicked_countにすべて含まれているため、「カバリングインデックス」が成立します。この場合、テーブルへの戻りが不要となるため、わざわざ主キーのクラスタインデックスを経由する必要もなく、効率的にインデックスだけでクエリを完結できます。
那如果故意加上where条件呢?
じゃあ、意図的にWHERE条件を付けてみたらどうなる?
1 | SELECT * FROM gpt_simplify_paper |

执行顺序是先where再order by。Extra里没有Using filesort,所以在where时就用到了索引,where筛选完的数据也自然有序了。order by的时候就不用再内存排序了。
所以由此学到了一个技巧:当select的字段超过了order by索引的范围(即需要回表),可以故意加上where条件筛选order by索引字段,这样在where时就可以利用索引排序了
実行順序は、まずWHERE、その後にORDER BYです。Extraに「Using filesort」が表示されていないことから、WHERE句の処理時点でインデックスが利用されており、その結果得られたデータは既にソートされた状態になっています。そのため、ORDER BYの段階でメモリ上でのソート処理は不要になります。
学んだ教訓:SELECTするカラムがORDER BYに使われているインデックスのカラム範囲を超えている場合(つまり「テーブルへの戻り」が発生する場合)、わざわざWHERE句でインデックス対象のカラムに対して絞り込み条件を明示的に指定することで、WHERE処理時にインデックスによるソートを活用できるようになります。
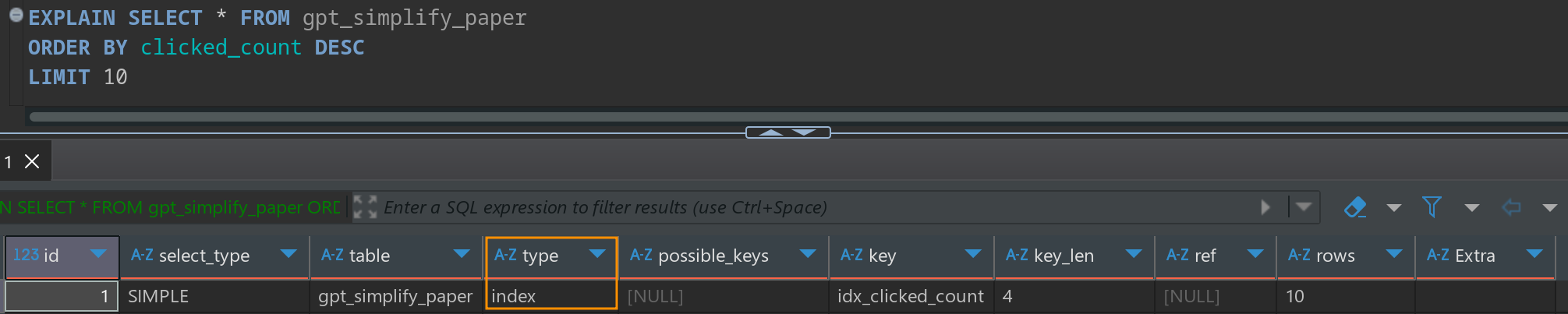
后来我还发现,即使select *没法覆盖二级索引,但如果加上了limit,也会走索引
その後、SELECT * が二次インデックスをカバーできなくても、LIMIT を追加することでインデックスが使用されることがあることに気付きました。
参考
https://www.bilibili.com/video/BV1cw411j78r
https://dev.mysql.com/doc/refman/8.0/en/order-by-optimization.html
- Title: 241004_order by到底走不走索引 ORDER BYは一体インデックスを使うのか?
- Author: Haoliang Tang
- Created at : 2024-10-04 00:00:00
- Updated at : 2025-04-30 00:10:06
- Link: https://hl-tang.github.io/2024/10/04/241004_order by到底走不走索引/
- License: This work is licensed under CC BY-NC-SA 4.0.